161762 Multivariate Analysis for Big Data
Lecture 11: Cluster Analysis Part 2
Fall 2026
K-means method
1. Select inputs.
Select k cluster centers.
Assign cases to closest center.
Update cluster centers.
Re-assign cases.
Repeat steps 4 and 5 until convergence.
Training data
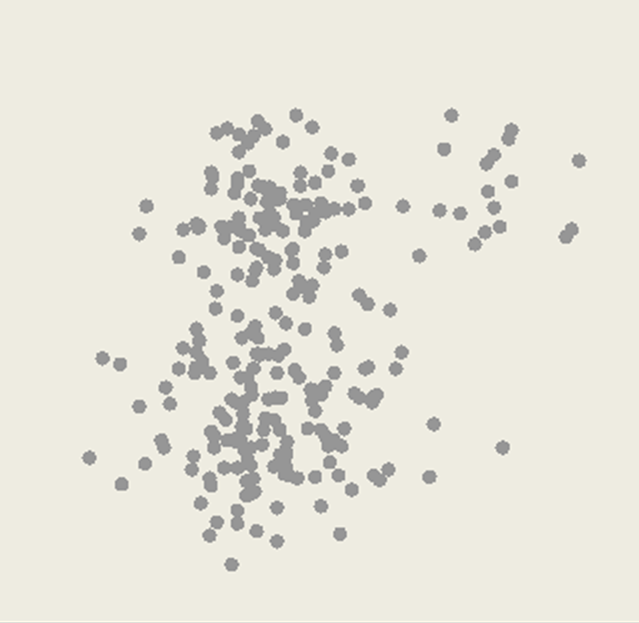
K-means method
- Select inputs.
2. Select k cluster centers.
Assign cases to closest center.
Update cluster centers.
Re-assign cases.
Repeat steps 4 and 5 until convergence.
Training data
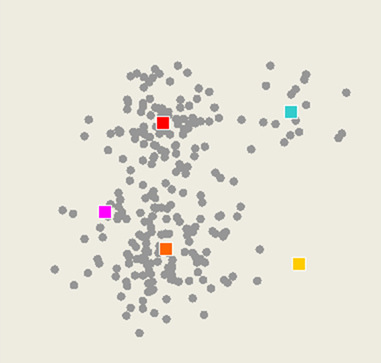
K-means method
Select inputs.
Select k cluster centers.
3. Assign cases to closest center.
Update cluster centers.
Re-assign cases.
Repeat steps 4 and 5 until convergence.
Training data
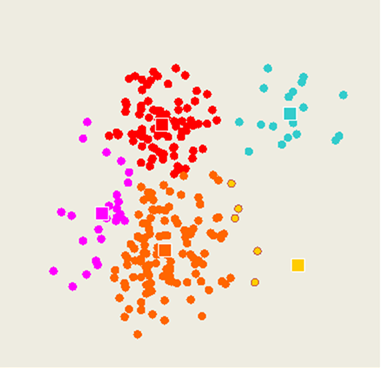
K-means method
Select inputs.
Select k cluster centers.
Assign cases to closest center.
4. Update cluster centers.
Re-assign cases.
Repeat steps 4 and 5 until convergence.
Training data
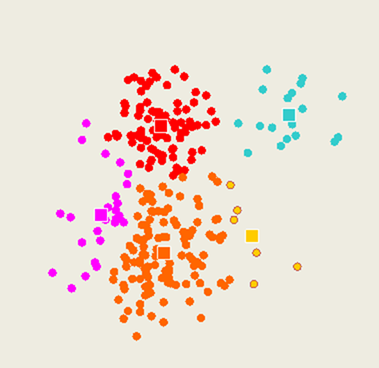
K-means method
Select inputs.
Select k cluster centers.
Assign cases to closest center.
Update cluster centers.
5. Re-assign cases.
- Repeat steps 4 and 5 until convergence.
Training data
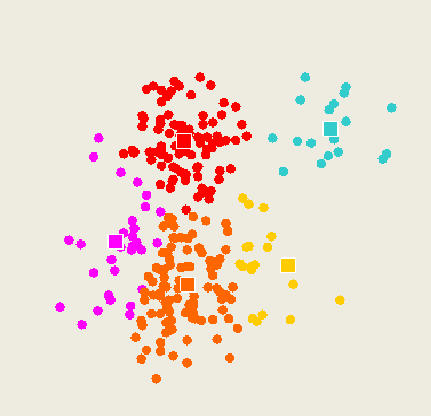
K-means method
Select inputs.
Select k cluster centers.
Assign cases to closest center.
4. Update cluster centers.
- Re-assign cases.
6. Repeat steps 4 and 5 until convergence.
Training data
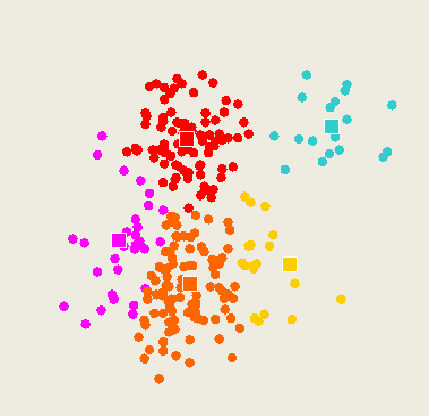
K-means method
Select inputs.
Select k cluster centers.
Assign cases to closest center.
Update cluster centers.
5. Re-assign cases.
6. Repeat steps 4 and 5 until convergence.
Training data
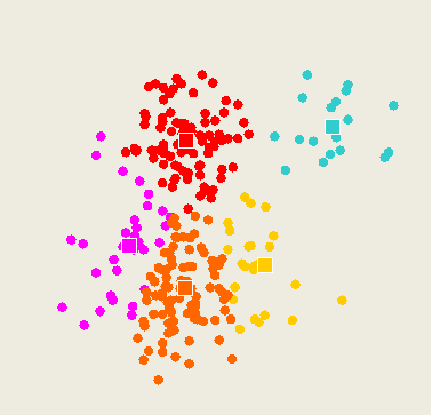
K-means Considerations
The results space is dependent on the starting point.
Within SS can fall into local minima.
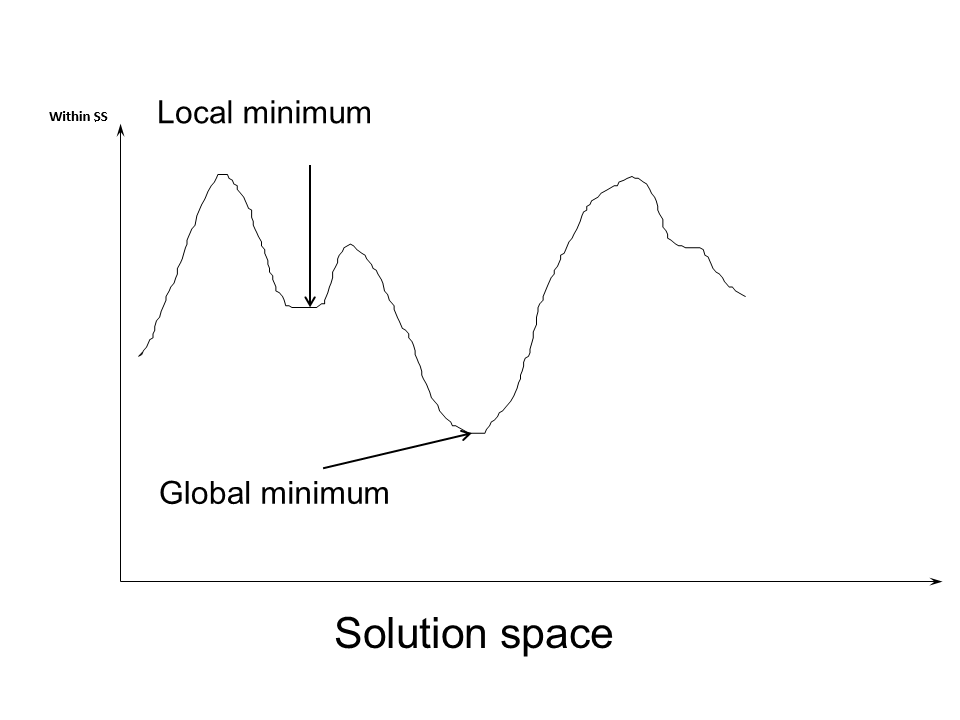
Example


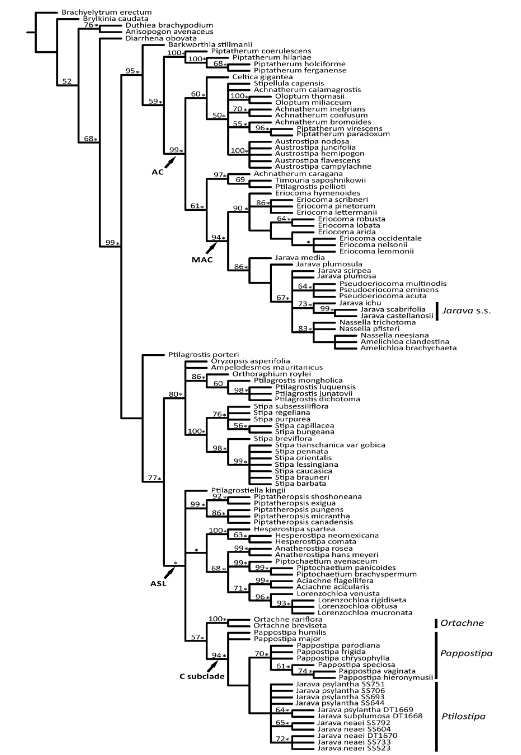
Example Dendrogram
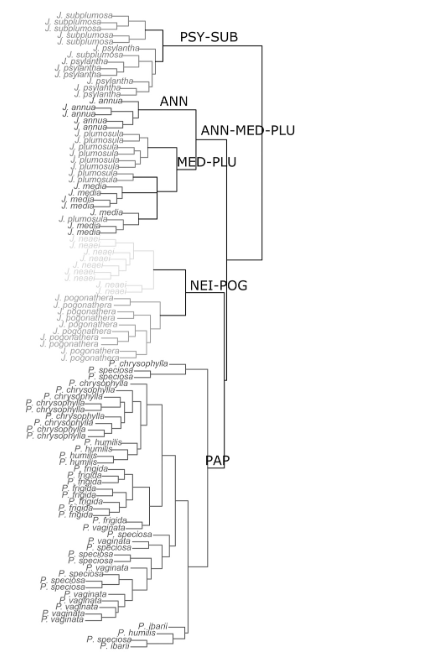
Example PCoA (Formal MDS)
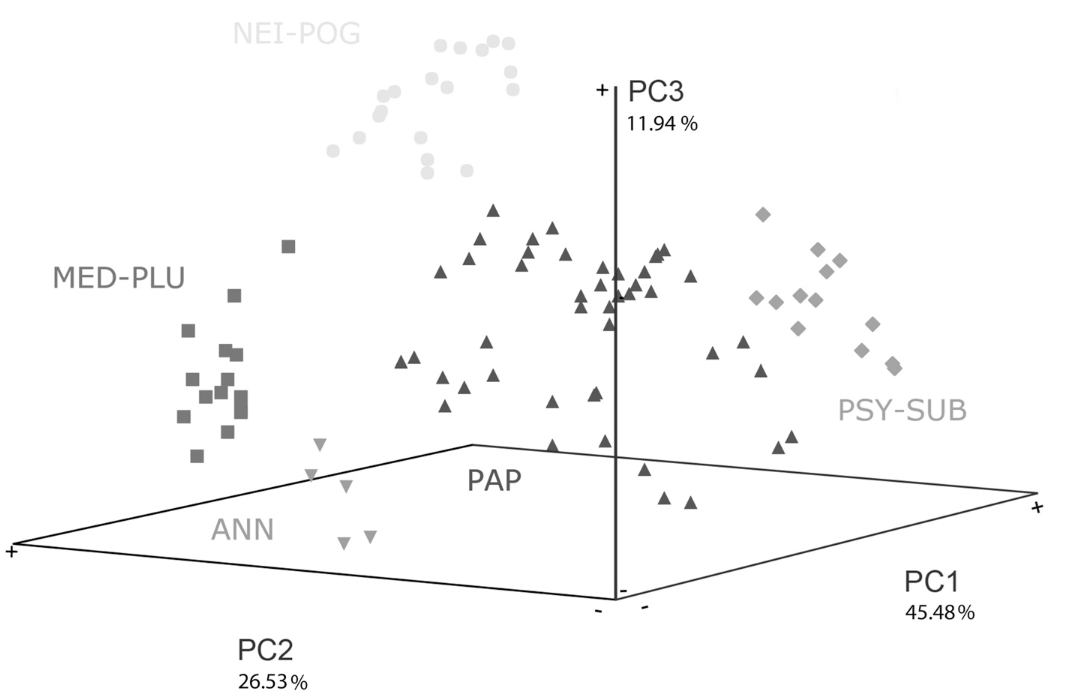
Example profiling